
Today I learned that Google will index a domain name that has not been registered. Ever. As in no one has ever registered the domain name, the domain name is available for registration by anyone, and someone could register it if they met the requirements by the domain name registrar. This one has me shaking my head a bit. This is a perfect example of Google going overboard in their crawling and indexing, and their policy of insisting to index (and potentially rank) web pages whose owners have specifically told them not to. But with all of the recent deindexing issues and the fact that Google has been dropping pages out of the index, them indexing domains that aren’t even registered is concerning to me.
Domain Name Example
This latest example of a domain name that Google’s indexing without even having been registered, is, what I would call an “edge example”. The situation is rather a unique setup by the domain registrar. I’m not quite sure if this actually meets ICANN rules and regulations, and I haven’t seen it before. Perhaps someone more familiar with ICANN rules and regulations would enlighten me and explain if this is actually allowed.

The domain name includes my name, Bill Hartzer. The domain name, in this case, is billhartzer.nom.za. If you go to billhartzer.nom.za you’ll see a page that delivers a “200 OK” header response. It’s actually a page, so that could be quite confusing for the search engines. If you go to a random string, though, like http://billhartzer123.nom.za/, you will see the same message. There is an actual page that shows up, saying that it hasn’t been registered. (By the way, I’m linking to http://billhartzer123.nom.za/ to see if Google will see it and index it, as well.)
Here’s the text of the page, saying that it’s not registered:
“billhartzer.nom.za” is not registered.
You have reached this page because you have made a request for a domain that does not exist. Wildcard Records give you the ability to map all (or a section) of the records in your domain. Wildcard records can be A, CNAME, or HTTP Redirection Records. Any record not previously defined (i.e. not registered) with its own subdomain, will resolve to the IP of the wild card.
NOM.ZA has a wildcard A record pointing to this web page for statistical analysis of domain queries that have not been registered. These domains can not be used for mail, webservers, pages, commerce or anything else useful, until they are in fact registered.
This is compliant with RFC 4592
If you comply with the Conditions of Registration you can register the domain name here: NOM.ZA Home Page.
Google will, in fact, index domain names that have been registered in the past, had web pages on them, and they are expired domains, for example. There are domain names that are indexed in Google because they have had content on them in the past, and they have been indexed, which is normal. Even expired domain names that are listed in GoDaddy’s auctions, or example, can be indexed, But in this case, the domain name isn’t registered. I cannot find any record that it has been registered in the past. I have not looked at the WHOIS history via Domain Tools to see if it was registered in the past, that would explain this indexing. But it was just indexed today. Here’s what I actually have done to see if there was a former site on this domain, and why I’m scratching my head on this one:
- If you go to billhartzer.nom.za/robots.txt you will see that the registrar is actually telling the search engines NOT to index the page. Yet Google actually is indexing the page.
- Archive.org does not have any record of the billhartzer.nom.za page, so that’s one indication that it most likely was not a website at any point and didn’t contain a site.
- I could not find any links to billhartzer.nom.za, checking Majestic.com.
Yet I did get a Google Alert today with this URL, as I have an alert set up for my name Bill Hartzer, and this domain name is indexed in Google, and has just been indexed.
Google Indexing Pages Despite Directive
A few years back, Google decided that they would index (and actually potentially rank) pages whose site owners tell them not to crawl via the robots.txt file. Many website owners who aren’t that technical will attempt to stop the search engines from “indexing” their web pages by putting a disallow directive in their robots.txt file. Many non-technical site owners think that this is enough to stop the search engines from “indexing” their pages. In fact, it had been this way for many, many years, which had been the internet standard. Don’t want search engines indexing your stuff? Put a disallow directive in the robots.txt file and they won’t. That’s been the standard protocol. Yet Google has decided to still index those pages whose site owners told them not to do so. Google’s using a “loophole” (and yes, I’m calling a loophole), trying to justify their actions.
According to Google, site owners are telling them not to CRAWL a page. So, that doesn’t mean they can’t INDEX the page. So, technically, now, in order to stop Google from actually showing a URL in the index, you have to ALLOW them to crawl a page (don’t disallow it in robots.txt) and use a noindex tag on the actual page you don’t want them to index. An alternative might be to use a canonical tag on the page and point that canonical tag to another URL on the domain name or, in fact, another URL on another domain name. Keep in mind, though, that doing that can have have its consequences, and some have been taking advantage of cross-domain canonical tags for negative SEO purposes.
The problem I have here, and the problem that I have had ever since Google implemented this policy of indexing pages despite a directive not to in the robots.txt file is the understanding by non-technical site owners. The problem here is that someone who, let’s say, is a blogger and not very technical. They set up a WordPress blog, and check the box “discourage search engines from indexing this site.” Google EVEN HAS A FEATURED SNIPPET FOR THIS:
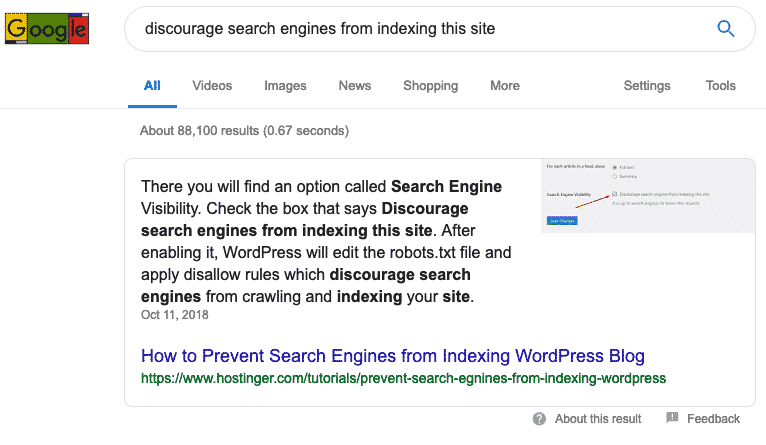
To someone who is NOT an technical SEO, “discourage search engines from indexing this site” means that if you tell search engines to not index their site, their web pages and blog posts will NOT show up in Google. But this is WRONG, according to Google. It actually means quite the opposite. It means that if you click that box in WordPress, and include a disallow directive in the robots.txt file, then the search engines (meaning Google) can STILL index your pages, and they can actually rank for keywords. That’s just wrong, in my opinion. It’s misleading to people who don’t know the Ins and Outs of SEO, and how search engines really work.
Website Example
Let’s look at an example of this. Let’s take Mary, for example. She has some really personal things to say, and she loves to write. To keep a journal of sorts. She decides to make a blog but she does NOT want the search engines to index her posts, as they’re personal, and the subject and topic of posts could get her in trouble. But she the posts are really good, and she tells some personal friends about the blog. One of those friends tweets the URL. The friend wants others to read it, knowing it’s an anonymous blog and not connected to Mary publicly. Yet Google decides to index that URL. Others see the URL via the Tweet and others start to share it and link to the post. Google sees the Tweets, they see the links, and they decide to rank it because it’s a popular post. Or they simply decide to index pages because they’ve seen Tweets and links to the URLs of posts. Yet Mary, in her mind, told the search engines NOT to index it. Mary’s furious at Google for “indexing” the site despite her telling them NOT to index the site.
I know the case of Mary and her blog is an example, and, granted, you could say it’s “far fetched.” But this example illustrates the fact that non-technical people actually think that telling the search engines NOT to index their stuff means “don’t show my pages or site in your search engine results.”
The case of my name, Bill Hartzer, being indexed and showing up in Google on a domain name that isn’t even registered, is, quite simply, crazy. Not only is the domain name registrar telling Google not to index it–the content on the page even tells the visitor that the domain name isn’t registered. Hey Google, can you take a hint? Why are you indexing domain names that aren’t even registered?