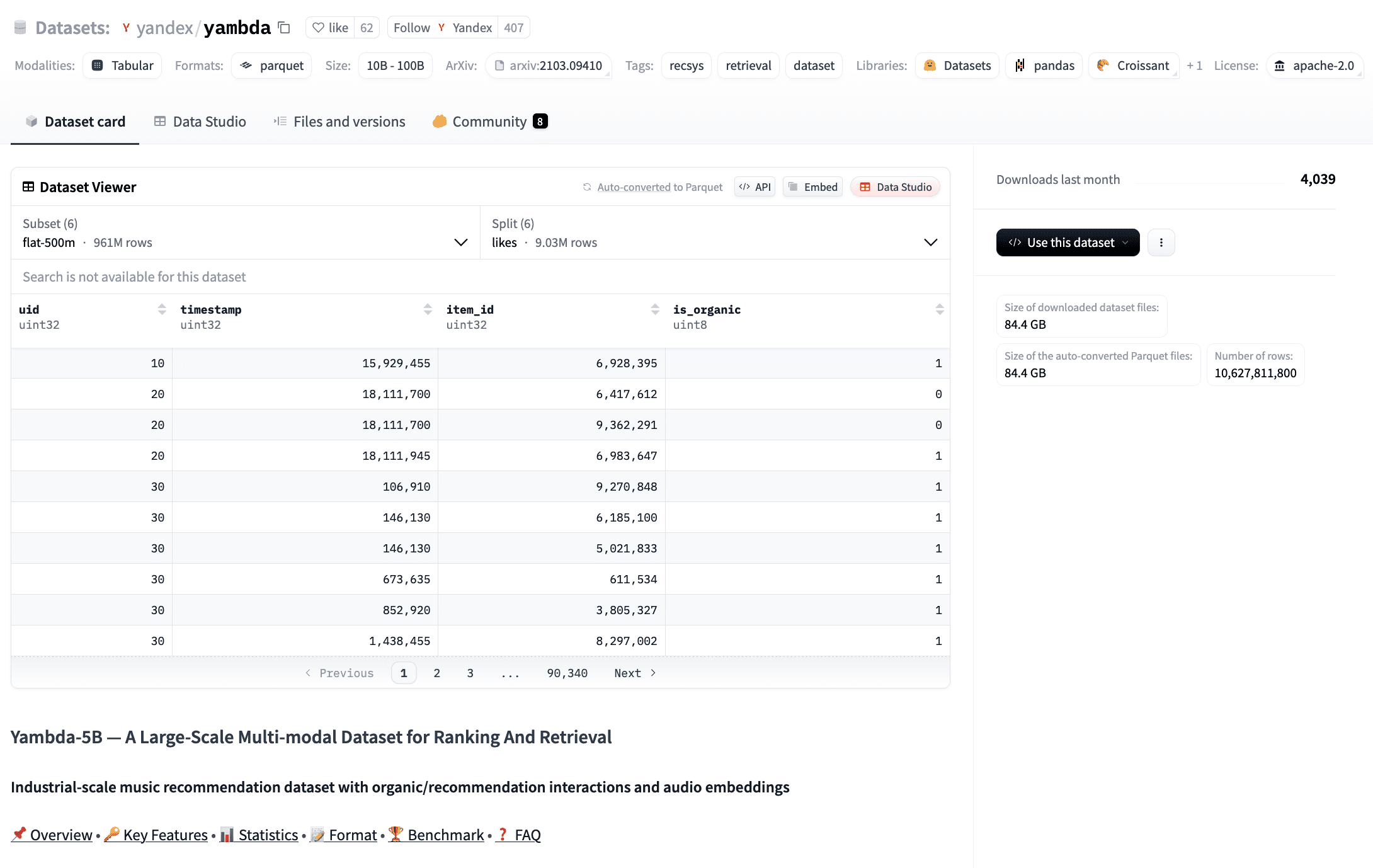
Yandex has released what it’s calling the largest publicly available dataset for training and evaluating recommender systems. The dataset, dubbed Yambda (Yandex Music Billion-Interactions Dataset), contains nearly 5 billion anonymized user interactions collected over ten months from its music streaming service, Yandex Music.
The data includes listens, likes, dislikes, and the timing of each event. Researchers, developers, and startups can now study user behavior at scale—something that was previously limited to tech giants with locked-down data.
Why This Matters
Strong recommendation models depend on training data that mirrors actual user behavior. Most existing public datasets don’t come close.
Spotify’s dataset contains playlists, but not enough behavioral detail. Netflix’s well-known dataset lacks timestamps and has been outdated for years. Criteo’s click logs focus narrowly on ads and are poorly documented.
That leaves researchers developing models in conditions that don’t reflect the real world. When those models are applied commercially, they fail to deliver. Yandex’s release aims to change that.
What’s Inside Yambda
Yambda draws from the listening habits of roughly one million users on Yandex Music. It features 4.79 billion user interactions across 9.39 million tracks. These include:
- Implicit feedback like listening activity
- Explicit actions such as likes, dislikes, and even the removal of a reaction
- Audio embeddings, meaning vector data created from the music itself using neural networks
- A flag that marks whether a user found a track on their own or through a recommendation
- Timestamps on every action, allowing for behavioral sequence analysis
The data is anonymized. Both users and tracks are assigned numeric identifiers to comply with privacy standards.
How It’s Packaged
Researchers can access the dataset in three different sizes:
- 5 billion events for enterprise-grade experimentation
- 500 million events for mid-level projects
- 50 million events for lightweight models or limited computing power
The files come in Apache Parquet format, compatible with tools like Spark, Hadoop, Pandas, and Polars. That flexibility makes it easier to work across platforms without reshaping the data.
How It’s Evaluated
Yandex didn’t stop at releasing data. The company also provided baseline models for testing. These include algorithms like ItemKNN, iALS, BPR, SANSA, and SASRec. To measure results, the dataset uses common evaluation metrics:
NDCG@k (ranking quality)
Recall@k (how many relevant items are retrieved)
Coverage@k (variety of items recommended)
Instead of artificially chopping off user history for testing, Yambda uses a method called Global Temporal Split (GTS). This keeps time-sequence data intact and mirrors how real-world systems work—where future data isn’t known in advance.
Making Big Data Useful Again
Yandex’s release gives smaller teams and academic labs access to data they couldn’t otherwise get. Startups can test recommender models without scraping together their own datasets. Researchers can try out new techniques without relying on stale data from 2010.
And because the dataset includes both what users liked and what they skipped or rejected, it supports a broader set of experiments—spanning music, retail, and content recommendations.
Where to Get It
Yambda is now available on Hugging Face, the popular open-access platform for machine learning models and datasets. Researchers can begin working with the dataset immediately.
Final Thoughts
This release marks a rare move in an industry where big data often stays locked behind company doors. By opening up billions of real-world interactions, Yandex is giving the research community a real chance to improve how recommendations are built—and tested.
For anyone working on AI that suggests music, videos, products, or anything personalized, this dataset changes the playing field. It’s one of the few times the public gets a peek behind the curtain of a major streaming platform—and the chance to build something better with it.